streamify
Streamify
A data pipeline with Kafka, Spark Streaming, dbt, Docker, Airflow, Terraform, GCP and much more!
Description
Objective
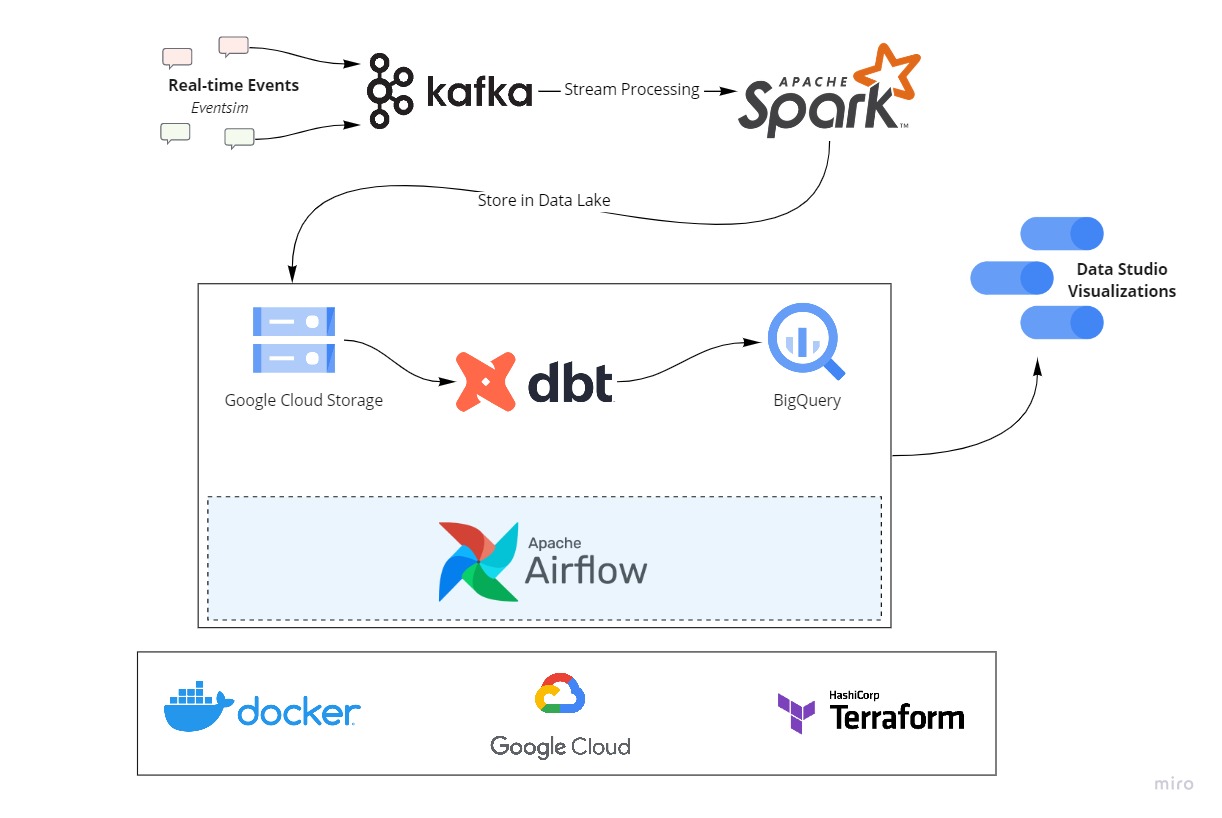
The project will stream events generated from a fake music streaming service (like Spotify) and create a data pipeline that consumes the real-time data. The data coming in would be similar to an event of a user listening to a song, navigating on the website, authenticating. The data would be processed in real-time and stored to the data lake periodically (every two minutes). The hourly batch job will then consume this data, apply transformations, and create the desired tables for our dashboard to generate analytics. We will try to analyze metrics like popular songs, active users, user demographics etc.
Dataset
Eventsim is a program that generates event data to replicate page requests for a fake music web site. The results look like real use data, but are totally fake. The docker image is borrowed from viirya’s fork of it, as the original project has gone without maintenance for a few years now.
Eventsim uses song data from Million Songs Dataset to generate events. I have used a subset of 10000 songs.
Tools & Technologies
- Cloud - Google Cloud Platform
- Infrastructure as Code software - Terraform
- Containerization - Docker, Docker Compose
- Stream Processing - Kafka, Spark Streaming
- Orchestration - Airflow
- Transformation - dbt
- Data Lake - Google Cloud Storage
- Data Warehouse - BigQuery
- Data Visualization - Data Studio
- Language - Python
Architecture
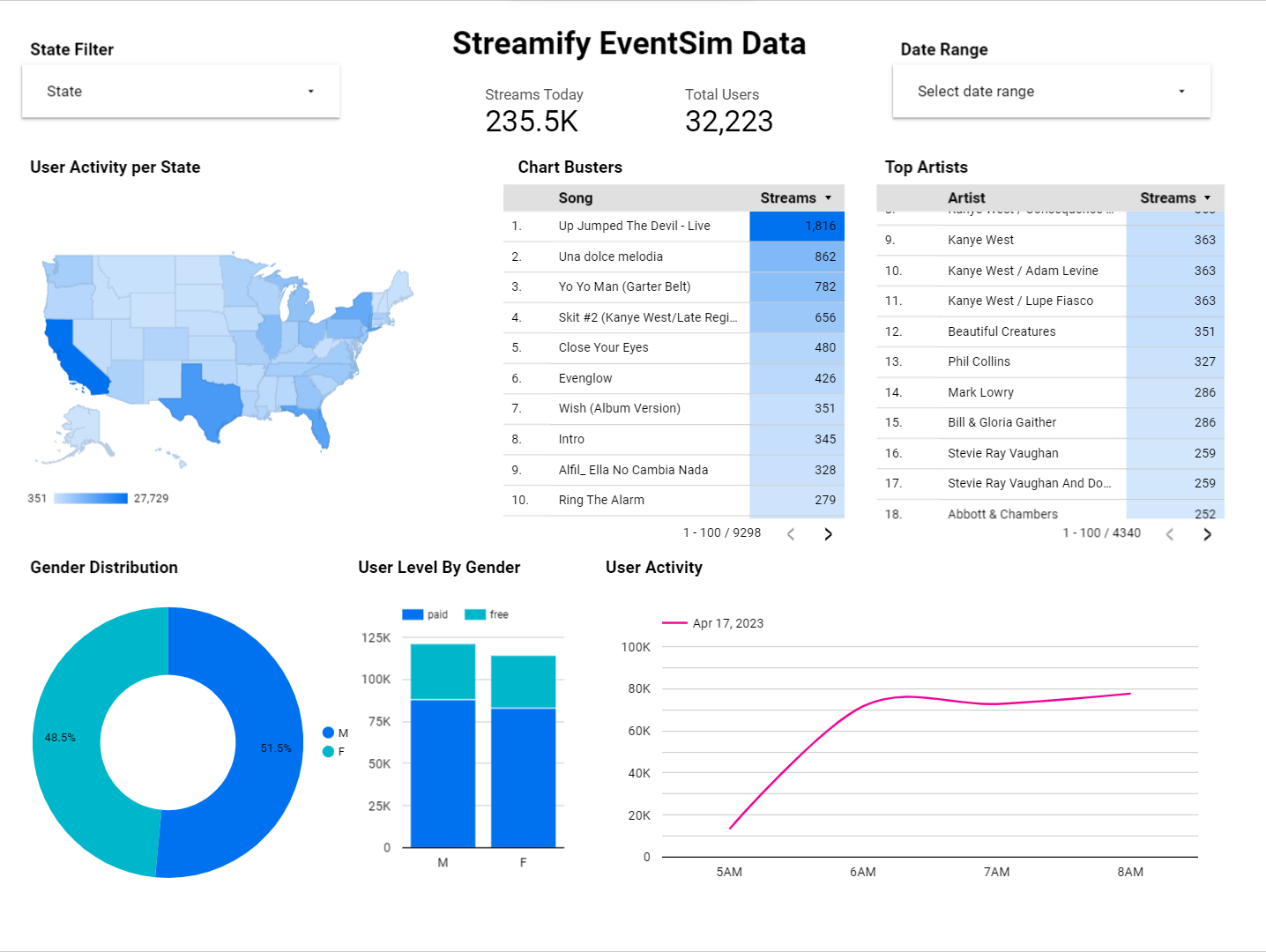
Final Result
Setup
WARNING: You will be charged for all the infra setup. You can avail 300$ in credit by creating a new account on GCP.
Pre-requisites
If you already have a Google Cloud account and a working terraform setup, you can skip the pre-requisite steps.
- Google Cloud Platform.
- Terraform
Get Going!
A video walkthrough of how I run my project - YouTube Video
- Procure infra on GCP with Terraform - Setup
- (Extra) SSH into your VMs, Forward Ports - Setup
- Setup Kafka Compute Instance and start sending messages from Eventsim - Setup
- Setup Spark Cluster for stream processing - Setup
- Setup Airflow on Compute Instance to trigger the hourly data pipeline - Setup
Debug
If you run into issues, see if you find something in this debug guide.
How can I make this better?!
A lot can still be done :).
- Choose managed Infra
- Cloud Composer for Airflow
- Confluent Cloud for Kafka
- Create your own VPC network
- Build dimensions and facts incrementally instead of full refresh
- Write data quality tests
- Create dimensional models for additional business processes
- Include CI/CD
- Add more visualizations
Special Mentions
I’d like to thank the DataTalks.Club for offering this Data Engineering course for completely free. All the things I learnt there, enabled me to come up with this project. If you want to upskill on Data Engineering technologies, please check out the course. :)